如果你最近有關注 AI 領域,可能會聽到「DeepSeek」這個名字。它是近期崛起的中國 AI 語言模型,號稱可以媲美 GPT-4,而最讓人關注的,是它的「開源」!也因為他的「開源」,讓很多大廠包含 Microsoft、nVidia、Amazon 都將 DeepSeek 接入到自己的 AI 工具裡(但同時又對他有諸多懷疑)。
所以「開源」代表什麼意思?對一般使用者又有什麼影響?另外,你可能還會聽到「蒸餾技術」這個專業術語,這又是什麼?這篇文章我會用最簡單的方式,讓你一次搞懂!
|
延伸閱讀 |
DeepSeek 什麼是?
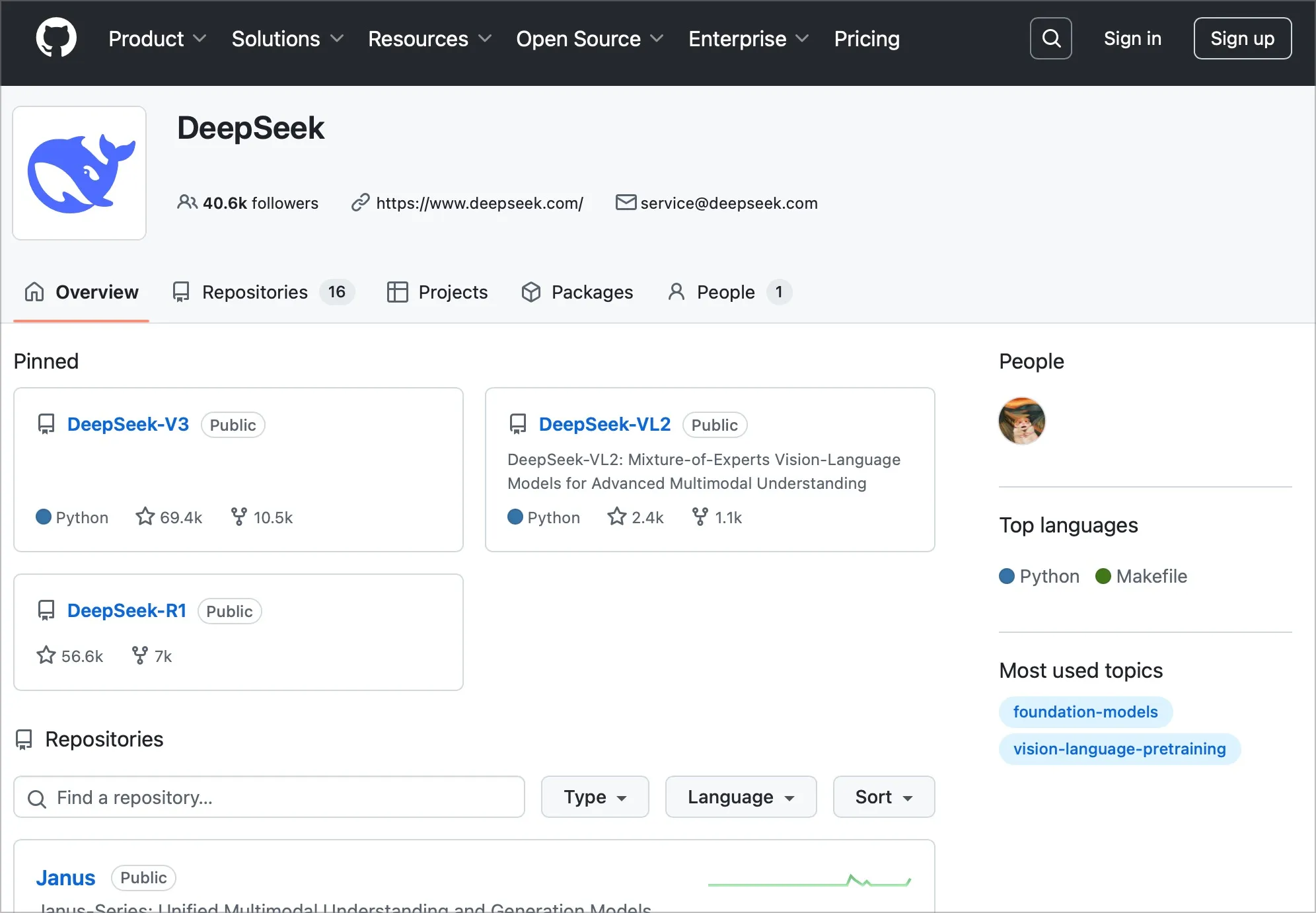
DeepSeek 是一款 AI 語言模型,類似於 OpenAI 的 ChatGPT 或 Google 的 Gemini,它能回答問題、寫作、翻譯、甚至生成程式碼。最特別的是,DeepSeek 團隊選擇將它「開源」,讓所有開發者都可以免費取得原始碼,甚至拿去改進、重新訓練,或整合到自己的應用程式裡。
▼ DeepSeek 開源程式碼在 Github 就可以下載
「開源」什麼是?
「開源」意思就是,這款 AI 模型的原始碼是公開的,任何人都可以查看、下載,甚至修改。這跟許多封閉式 AI 服務(例如 OpenAI 的 ChatGPT API,要使用會依照用量收費)很不同。簡單來說,DeepSeek 的開源讓更多人能參與改進 AI,讓 AI 更加透明,也降低了開發者的成本。
開源 = 技術免費
DeepSeek 開源也是類似的意思。DeepSeek 是一家專注於 AI 技術的公司,他們開發了一些強大的 AI 模型。開源後,這些模型可以被任何人免費下載、使用,甚至修改。
開源 ≠ 完全免費
雖然開源模型可以免費下載,但如果想讓它運作起來,還是需要一些成本。比如:
- 硬體成本:需要電腦或伺服器來執行 AI 模型。
- 維護成本:需要技術人員來管理和改良系統。
所以,開源比較像是「免費送這本電腦 DIY 組裝的書籍看你想怎麼使用都行,但你自己要準備電腦零件和組裝工具」。
開源的好處
對開發者或服務提供者(像是微軟、nVidia、Amazon)而言,可以免費使用 DeepSeek 的技術,開發、整合進自己的 AI 應用,省下從頭研發的成本。
對一般使用者而言,可以有更多便宜又好用的 AI 工具,因為上面提到的這些開發者、服務提供者的開發、整合成本降低了。
▼ nVidia NIM 已經可以部署 deepSeek R1
DeepSeek 與 OpenAI 相比
| DeepSeek(開源) | OpenAI(封閉式 API) | |
| 成本 | 免費 (但需自行負擔運算成本) |
按 Token 使用量計費 (例如 GPT-4 API) |
| 硬體需求 | 需要 GPU 或伺服器部署 | 不需要自行管理硬體,由 OpenAI 雲端處理 |
| 使用彈性 | 可自行修改、優化,甚至重新訓練 | 只能使用官方提供的 API,無法自行修改 |
| 適合對象 | 適合有技術能力的開發者、大型企業 | 適合個人開發者、企業快速開發 AI 服務 |
| 長期成本 | 若流量大,長期運行成本較低 (只需負擔伺服器費用) |
長期使用成本高,隨 Token 增加費用不斷上升 |
▼ OpenAI 依照不同模型、不同用量有不同的價格

「蒸餾技術」是什麼?
之所以會有「蒸餾技術」這個名詞的出現,主要是因為 DeepSeek 被懷疑使用「蒸餾技術」。雖然在 AI 藉這是常見的做法,但是 OpenAI 的服務條款中已經明確禁止,所以若 DeepSeek 確實使用蒸餾技術來打造自家模型,將可能被 OpenAI 控告侵權。
蒸餾 = 把大模型變小
AI 模型就像一個超級複雜的大腦,越大的模型通常越聰明,但也越耗資源。比如,ChatGPT 這樣的模型需要強大的伺服器才能運行,成本非常高。
「蒸餾技術」就是一種把大模型變小的方法。你可以把它想像成「把一本厚厚的百科全書,精簡成一本輕便的手冊」,雖然內容變少了,但最重要的知識都還在。
▼ 經典的「老師」與「學生」模型
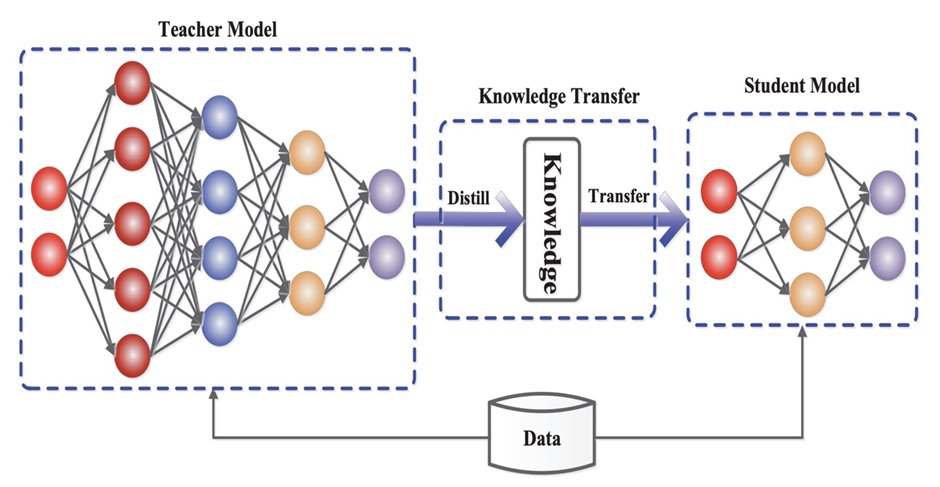
蒸餾技術的好處
儘管爭議重重,但是蒸餾技術本身是很不錯的東西。
更省資源
小模型需要的硬體設備更便宜,執行速度也更快。
更適合行動裝置
因為不需要太多資源,所以可以在手機、平板等設備上執行,不需要依賴雲端伺服器,使用上更加彈性。
降低成本
開發者和企業可以用更低的成本部署 AI 應用,消費者也可以用更低的費用使用這些 AI 工具。
是蒸餾還是抄襲?
有些人會覺得蒸餾和抄襲很像,但其實這兩者是有點不太依樣的。
| 蒸餾 | 抄襲 | |
| 核心概念 | 讓小 AI 模型學習大模型的知識,保留核心智慧 | 直接複製另一個 AI 模型的內容或結果 |
| 如何學習 | 透過模仿大模型的行為來學習,而不是直接拷貝 | 未經學習過程,直接盜用競爭對手的數據或模型 |
| 合法性 | 若使用自己的 AI 進行蒸餾,通常是合法的 | 未獲授權使用他人的模型或數據可能涉及侵權 |
| 運作方式 | 使用公開數據或自家模型改良 AI,使其更輕量 | 抓取對手的 API 回應,或逆向工程還原 AI 模型 |
| 違法風險 | 蒸餾過程未使用未經授權的數據,則無違法風險 | 可能違反智慧財產權,面臨法律訴訟 |
| 簡單比喻 | 老師教學生解題思路,學生學會後自己答題,而不是抄老師的答案 | 學生直接偷看老師的答案,寫在自己的考卷上交出去 |
目前市場上的懷疑是,DeepSeek 是否透過 OpenAI 的 API 來訓練自己的 AI?
- 如果它 蒸餾自己的模型,那是正常技術發展,沒有問題。
- 如果它 大量抓取 GPT-4 的回應,並用來訓練自己的模型,那可能就涉及侵權爭議。
到底事實是如何,目前還有待釐清,但是「蒸餾」與「抄襲」差異的核心原則是 有沒有學習過程,而非直接複製別人的結果。
總結:DeepSeek 的「開源」與「蒸餾」
DeepSeek 的「開源」讓 AI 技術變得更透明,開發者可以免費使用、修改,甚至整合到自己的應用中,當然要運作的話就需要自行負擔硬體成本。
而「蒸餾技術」則是一種讓 AI 模型變小、計算更有效率的方法,能降低運算需求,但也可能涉及技術爭議。簡單來說,開源帶來了更多創新機會,而蒸餾技術則讓 AI 更輕量、更普及,這兩者都是 AI 發展的重要趨勢!
延伸閱讀》
DeepSeek 還能註冊嗎?驗證碼發送失敗怎麼辦?一招解決方法告訴你
DeepSeek 成本造假、抄襲 ChatGPT、敏感話題爭議一次了解
開槍了!DeepSeek 在義大利 / 德國 / 愛爾蘭被要求從 App Store 下架、管制
如果想知道更多關於 Apple 的消息、教學、小技巧或是科技新知,一定要點擊以下任一 LOGO,追蹤我們的 Facebook 粉絲團、訂閱 IG、YouTube 以及 Telegram。